Test Overview
The benchmark results below are from a single thread on a process with the thread-affinity set except two. The BPlusTree(Threaded) and obviously MySql were not constrained. All data used during the test was generated before the test ran. The number displayed in the logarithmic horizontal axis is the average number of operations completed per second. This is the worst average of the last 5 of 8 total runs.
Benchmark Results
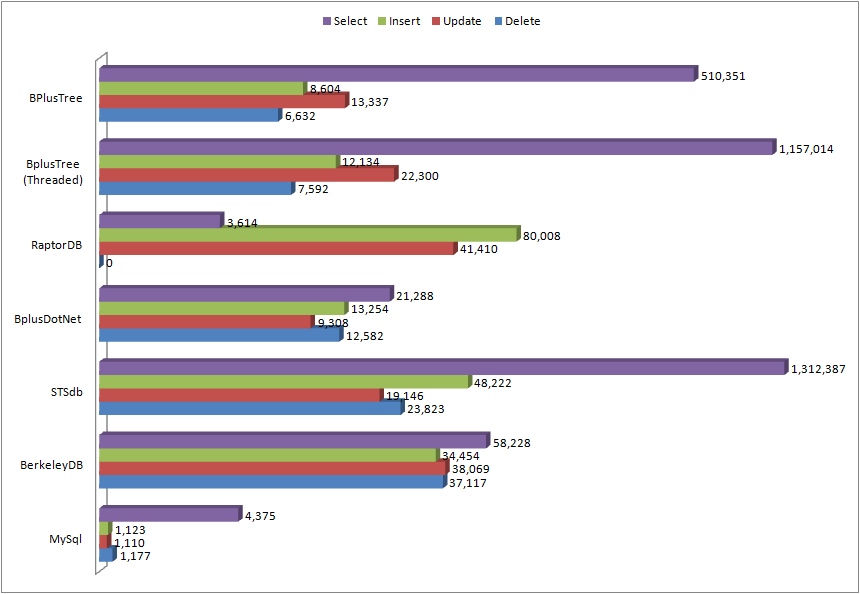
BPlusTree
The strong showing here is most certainly the select time. BPlusTree and STSdb outpace all the rest by a full order of magnitude. As you can see though the insert, update, and delete times, though respectable, are not near some of the other options.
BPlusTree (Threaded)
This test used 4 CPUs and 4 threads to produce the throughput shown. The general goal here was to demonstrate the throughput was higher than a single-threaded test. Showing a 50% gain on insert and update times across 4 threads gives you an idea of the level of resource contention.
So why are no other tests repeated as a multi-threaded version? Well quite simply I tried and all of the other libraries either did not support threading, or failed to prove thread-safe during testing. Raptor DB corrputed state and hung the application. Even the beloved Berkeley DB blew up on threaded deletes both in transactional and non-transactional modes. While MySql worked the benefits in performance were not worth noting here.
RaptorDB
Although this library did produce some good numbers on modifications I really have to call this one a non-starter. Not only can you not close/unload it, but it basically does nothing more than append the data to a log and perform a manual lookup (at least until their indexing thread catches up). This, IMHO, is just a nasty design flaw and shows up well in their blazing slow seek performance. I managed to crash and/or corrupt the store several times, even on a single thread. As for the claimed multi-threading capabilities of this library it’s a joke, this library is far from thread safe. Frankly you would be better off appending the data to a single file with a Dictionary<K,V> to give you the file offsets. That is basically what it seems to be doing behind the scene, even so far as to make you call SaveIndex() to persist the index. (Update: Review of RaptorDB version 1.7)
BPlusDotNet
Nothing spectacular here unless you need Java/C++ compatibility which is nice. The select times on this seem to be sub-par and there is no support AFAIK for multi-threading. All-in-all it behaved well in every single-threaded test. Unlike RaptorDB it seems stable enough to use in the right environment. It even performs much better than my own for deletes, I’ll have to take a look at that ;)
STSdb
This library really blew me away. Although I could not find any documentation about multi-threading it is so wicked fast I’m not sure I care. The only down side is that this library is GPL licensed unless your willing to pay for commercial use. I don’t know what the cost of it is but if you need that kind of performance it may be worth investigating. Definitely a two-thumbs-up library if you have plenty of ram and hard-drive space to work with ;)
BerkeleyDB
Again I was surprised to see this outpace a fully managed solution by a margin of 3:1. Outside of it’s relatively slow select speed it was a consistent high-performer. I will warn you that I was able to corrupt it’s state a few times, mostly in multi-threaded deletes which is why I did not post a threaded performance chart. If you’ve never worked with it, the library is cumbersome to work with due to the infinite number of options. I’ll also warn you to stay away from it’s transacted mode, with transactions enabled this performs very poorly especially for inserts (1350/sec).
MySQL
Just threw this in to give a comparison to a well-known RDBMS solution.
Resource Usage
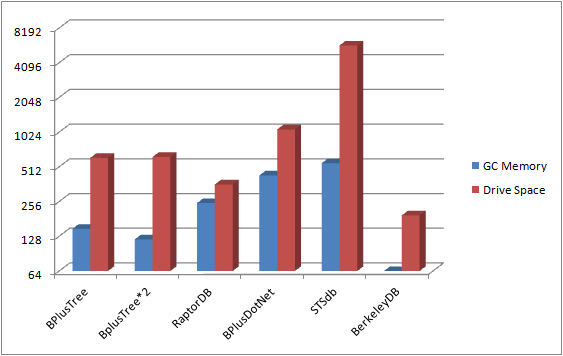
The chart above indicates kilobytes per 1000 records of 116 bytes. All considered everyone was close on resource usages except the clear winner and loser. I was using the GC for obtaining memory usage so Berkely does not have memory usage information; however, it’s disk cost was very good. The looser here is not really a looser based on it’s performance, but clearly we know where STSdb is getting all the performance from :)
Summary
Out of all the purely managed, free, and open source (non-GPL) I still think the BPlusTree stands out as a winner based on it’s low memory usage, fast seek times, and multi-threading support that actually works. If I were willing to buy it though I’d have to go with STSdb and just buy some more memory and hard-drive space :)
Trackbacks